
Interoperability with C is important for any system programming language, Rust is no exception in supplying proper support for this. And even if the C ABI is not standardized, it is considered stable and consistent on a given system. This allows it to be the perfect target for cross-language interoperability as well, be it the other language also supports C interoperability which is commonly the case. But C by itself gives direct access to a wide range of system functionality, platform APIs, libraries written in C, and well supported C wrappers to popular libraries, etc…
Rust is compatible with the C ABI through the use of extern "C" on function blocks to define it is externally linked and to have it conform to the C calling convention on the target system:
extern "C" fn foo(handle: *mut ::std::os::raw::c_void)
Any extern "C" functions are inherently unsafe so they can only be called from within unsafe blocks, so we usually resort to writing safe wrappers, which I’m not going to discuss in this article.
Structures need also to be declared for making a struct layout match the C one:
#[repr(C)]
struct Bar {
i: std::os::raw::c_int;
}
One of the complexity of interfacing with C is usually go from a header file to a binding.rs file containing the above described constructs. And while trying to write bindings for the AMD AMF library, I surveyed more than 30 bindings crates to have an idea of the different approaches people are taking for this task, so I’ll try to go through them while giving my opinion on which context they are more suitable to use.
Manual bindings writing
When the public API of a C library consists of a small amount of functions and structures and the library is stable enough not to warrant a lot of maintenance at each upgrade, it is usual to see bindings written by hand. The writer still needs to pay extra attention to some subtleties in the headers, like the use of ifdefs on the target being built which would be translated to #[cfg!(target_os = xxx)].
This has the benefit of not adding any extra build time dependencies or complex tools (or tools with complex dependencies) that automates the process that then need to be learned, maintained, etc… So in the sake of keeping it simple, I think this approach makes sense when the public surface of the library is comprehensibly small. The good news is that there is actually a lot of C libraries that make it a top priority to keep their public interface as small and as stable as possible.
So given the the public surface of a library is small, the initial cost of this approach is low as well making it a good starting point to assess down the road how much maintenance the bound library needs then if the initial assumptions don’t hold up, you can always migrate to automatic bindings generation.
Automatic bindings generation
Bindgen is a library that relies on clang-sys (a binding to libclang) to process a given set header files and generate the equivalent Rust declarations. It is also available through a CLI that wraps the library functionality. And as far as I can tell it’s one of the most popular binding generation tools for C.
One important aspect of using Bindgen, is that it doesn’t come with a bundled libclang, it relies on an LLVM installation to find it. So any non trivial installation will need the help of setting the LIBCLANG_PATH environment variable (on windows, the scoop based installation for example is an issue for example).
Ahead of time bindings generation
It is common to see ahead of time generated bindings in raw FFI bindings crates and if you are lucky you might find an accompanying shell script or documentation with the exact command used to generate the bindings. The maintainer of the crate would have ran the command on his machine and pushed the resulting file to the repo.
This means running bindgen through a shell to generate the different bindings and committing them to the repo, it is the responsibility of the maintainers to keep the library and the headers in sync (although it is simple to implement CI checks for this).
The complexity of this approach arises when the C library has per platform definitions. In that case either multiple bindings need to be generated or a less trivial generation scheme needs to be implemented. The problem with generating multiple bindings is that each time you update the library you either have to have a setup allowing cross target generation or you need to regenerate the target for each system, this can be annoying and introduce enough friction to have let the library go stale.
So when going with this approach, I think it important to have the author generate the bindings on multiple targets at least once to compare the output and make sure there is no differences that warrant multiple bindings.
Also if the library needs to be supported on targets that can’t run bindgen (or libclang to be more precise), it might be your only automatic generation option possible.
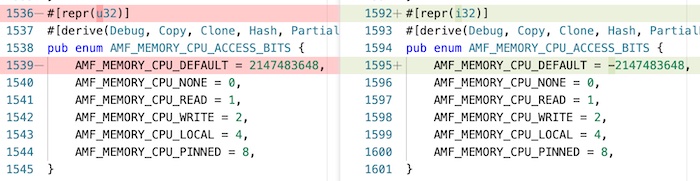
Per platform type definition:

Default enum type varies from windows to linux:
Just in time bindings generation
Instead of invoking the CLI version of bindgen, you include bindgen in the build process using it as a build dependency in your build script. The generation is documented through code which is always better. And you are guaranteed to have an up to date and generated bindings that match your target. Cross compilation needs to be handled as follows:
let target = env::var("TARGET").expect("Cargo build scripts always have TARGET defined");
let host = env::var("HOST").expect("Cargo build scripts always have HOST defined");
if target != host {
builder.clang_arg("-target").clang_arg(target);
// in some instances, you need to specify a sysroot, for example linux cross building from windows
if let Ok(sysroot) = env::var("SYSROOT") {
builder.clang_arg("--sysroot").clang_arg(target);
}
}
A additional note regarding this method and IDE support, since using the generated file is done through and include macro:
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
IDE have a problem tracing a definition in the outputted file, and hitting the “Go to Definition” button will bring you to the include macro line. But note that this doesn’t impact panic backtraces and debugging at least.
Hybrid generation
Some crates use features to support ahead of time and just in time binding generations and default to the ahead of time method. Leaving it the user of the bindings to use one or the other approaches.
In your Cargo.toml:
[build-dependencies]
bindgen = { version = "0.58.1", optional = true }
Your build.rs:
use std::path::PathBuf;
use std::{env, io};
#[cfg(feature = "bindgen")]
extern crate bindgen;
fn main() -> io::Result<()> {
let dst_file_path = PathBuf::from(
env::var("OUT_DIR").expect("Cargo build scripts always have OUT_DIR defined"),
)
.join("bindings.rs");
#[cfg(feature = "bindgen")]
{
bindgen::builder()
.header("amf/amf/public/include/core/Factory.h")
.raw_line("// Generated through amf-sys build script")
.parse_callbacks(Box::new(bindgen::CargoCallbacks))
.allowlist_type("AMF.*")
.allowlist_function("AMF.*")
.allowlist_var("AMF.*")
.generate()
.expect("Unable to generate bindings")
.write_to_file(dst_file_path)
.expect("Unable to write bindings");
}
#[cfg(not(feature = "bindgen"))]
{
let src_file_path =
PathBuf::from(env::var("CARGO_MANIFEST_DIR").expect("CARGO_MANIFEST_DIR not defined"))
.join("src")
.join("bindings.rs");
fs::copy(&src_file_path, dst_file_path).expect("Couldn't access pre-generated bindings!");
println!("cargo:rerun-if-changed={}", src_file_path.display());
}
println!("cargo:rerun-if-changed=build.rs");
Ok(())
}
In your lib.rs
#[cfg(feature = "bindgen")]
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
I’ve seen some implementations actually output the generated files to the the src directory to not rely on an include! marco. Although this might be tempting, it is one of the abuses that the scripts system allows, making it extra hard to use Bazel for example where the execution environment of all commands is virtualized. As suggested in the build script documentation, the build scripts should only write to the output directory.